Our Full-Text RSS application can extract article content in web pages through a combination of automatic content detection and site-specific extraction rules.
When a user encounters a problem extracting content from a particular site, we usually point them to our help page for writing custom extraction rules. That can not only be quite time consuming, but to do it, we assume users have an understanding of HTML and XPath. That’s a big assumption. If users can’t create extraction rules themselves, they’ll have to rely on us to do it. We’d much rather make the process easier and let users contribute their extraction rules to our repository so all users of Full-Text RSS benefit.
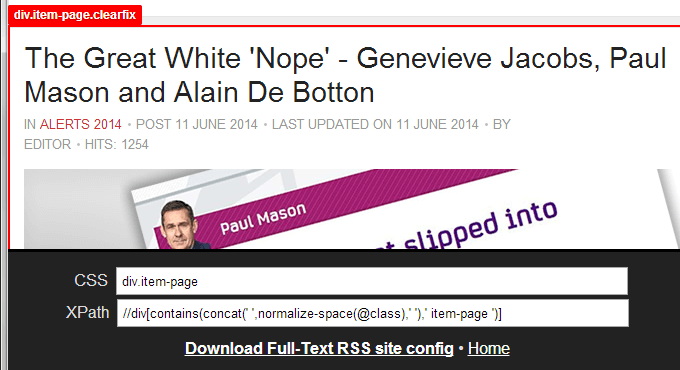
To that end, we’ve started work on a tool, still in the early phases, to let users create extraction rules through a simple point-and-click interface. At the moment the focus is on letting the user visually select the main content block that Full-Text RSS should extract. The tool will then generate the required XPath selector and offer a download link so the result can be saved to the appropriate Full-Text RSS folder.
Try it out
If you’re a Full-Text RSS user, please try it out and let us know what you think.
A few things to bear in mind:
- Try this on a recent version of Firefox, Chrome, or Opera.
- Content generated by Javascript will not be shown or accessible because Javascript from the source site is disabled (this is the same in Full-Text RSS).
- We are not yet testing the generated XPath with Full-Text RSS, so there is a small chance that it will not actually match the desired element due to differences in parsing. We plan on including such a test, and also testing the generated selector against the site’s feed to see if it finds matches on different articles.
Compared to browser developer tools
Many browsers already offer similar element selectors in their developer tools. The closest we came to finding what we were looking for is Firefox Developer Tools’ “Copy Unique Selector”. There are a few differences, however, in how we produce the CSS selector string. The aim of our tool is to create a unique selector which matches the content element not only on the current page, but also similar pages from the same site (e.g. a different article from the same news site). So, compared to Firefox Developer Tools’ Unique Selector:
- We do not use
:nth-childselectors as we think they can be quite brittle for the use we have in mind. If we can’t create a unique selector using the element name, class attribute, id attribute, or ancestor elements, we’ll simply give up and alert the user. - We ignore id or class attribute values which contain a sequence of 2 or more numbers, or a hyphen followed by a number. These often indicate article-specific ID numbers. For example,
#post-1117is a unique selector, but the 1117 is most likely an ID number associated with the article currently displayed on the page. A different article from the same site will likely have a different ID number, which means our selector will not match it.
Future
We hope to eventually reach a point where this can be integrated not only with Full-Text RSS, but with applications which rely on Full-Text RSS. Applications such as Push to Kindle, PDF Newspaper, and Wallabag. At that point we should be able to hide the CSS/XPath selectors from users and simply ask them to select the content block and click a button to have the extraction rules generated and saved.
Credits
We used a number of free software tools to create this. Most of the credit goes to the following projects:
- Andrew Childs’ DOM Outline
- Joss Crowcroft’s Simple JavaScript DOM Inspector
- Andrea Giammarchi’s CSS to XPath